Evaluation Framework

![]()
This repository contains a (software) evaluation framework to perform evaluation and comparison on node embedding techniques. It can be easily extended by also considering edges into the evaluation. The provided tasks range from Machine Learning (ML) (classification, regression, and clustering) and semantic tasks (entity relatedness and document similarity) to semantic analogies. The framework is designed to be extended with additional tasks. It is useful both for embedding algorithm developers and users. On one side, when a new embedding algorithm is defined, there is the need to evaluate it upon tasks it was created for. On the other side, users can be interested in performing particular tests and choosing the embedding algorithm that performs best for their application. Our goal is to address both situations providing a ready-to-use framework that can be customized and easily extended. A preliminary overview of the framework and its results can be accessed through A Configurable Evaluation Framework for Node Embedding Techniques.
We provide the framework as a command-line tool. We are working on the REST API development (you can inspect the dev branch) and we are providing it as API.
Please refer to https://mariaangelapellegrino.github.io/Evaluation-Framework/ to access the readme as a webpage.
Framework structure and extension points
It is a diagrammatic representation of the involved actors in the framework and their interactions. The blue boxes represent abstract classes, while the white boxes represent concrete classes. If A <<extends>> B, A is the concrete class that extends and makes the abstract behavior of A concrete. If A <<instantiates>> B, A creates an instance of B. <<uses>> B, A is dependent on B.
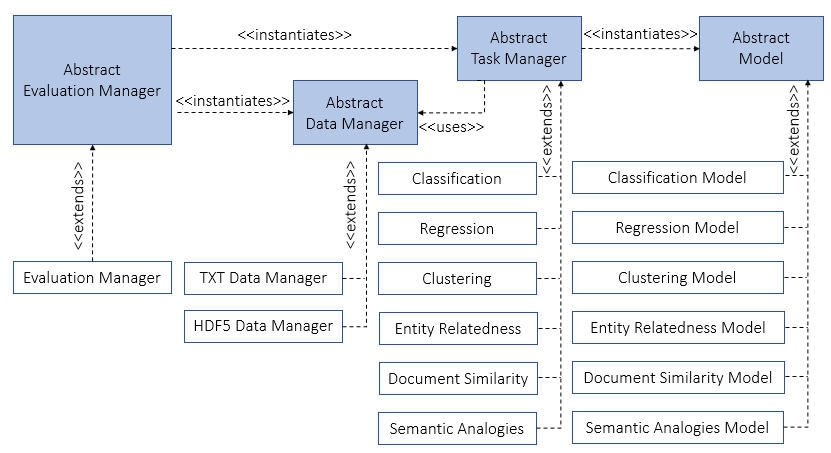
The starting point of the evaluation is the Evaluation Manager which is the orchestrator of the whole evaluation and it is in charge of
1) verifying the correctness of the parameters set by the user,
2) instantiating the correct data manager according to the data format provided by the user,
3) determining which task(s) the user asked for,
4) managing the storage of the results.
Depending on the file format, the corresponding data manager decides how to read the vector file content and how to manage the access to it (e.g., if the whole content has to be load in memory). Each data manager has to
1) manage the reading of the gold standard datasets,
2) manage the reading of the input file,
3) determine how to merge each gold standard dataset and the input file.
The behavior of the data manager is modeled by the abstract data manager, implemented by a concrete data manager based on the input file format and it refined by a task data manager.
Each task is modelled as a pair of task manager and model.
The task manager is in charge of
1) merging the input file and each gold standard file (if more than one is provided) (by exploiting the data manager),
2) instantiating and training a model for each configuration to test,
3) collecting and storing results computed by the model.
Each task can decide if the missing entities (i.e., the entities required into the gold standard file, but absent into the input file) will affect the final result of the task or not.
To extend the evaluation also to edges, it is enough to create a gold standard dataset containing edges and related ground truth.
Repository structure
- Evaluation-Framework/evaluation_framework contains
- abstract_evaluation: abstract class to supervise the whole evaluation
- abstract_dataManager: interface to manage a new input file format
- abstract_taskManager: interface which defines all the methods a new task has to implement
- abstract_model: interface to define a new model used by the task manager
- manager: check the correctness of the parameters and start the evaluation
- evaluationManager: implements the abstrac_evaluation interface
-
txt_dataManager and hdf5_dataManager: concrete dataManager which manage, respectively, the TXT and the HDF5 data format
- one folder for each implemented task which contains
- data folder with the dataset(s) by the task
- taskManager which implements the abstract_taskManager interface
- model which implements the abstract_model interface. For instance, about the classification task the folder Evaluation-Framework/evaluation_framework/Classification contains
- classification_model and classification_taskManager
- Evaluation-Framework/evaluation_framework/Classification/data folder that contains all the datasets used as gold standard.
- Evaluation-Framework/example folder contains several main files showing the different ways to initialize the framework
Tasks
The implemented tasks are:
- Machine Learning
- Semantic tasks
Each task follows the same workflow:
- the task manager asks data manager to merge each gold standard dataset and the input file and keeps track of both the retrieved vectors and the missing entities, i.e., entities required by the gold standard dataset, but absent in the input file;
- a model for each configuration is instantiated and trained;
- the missing entities are managed: it is up to the task to decide if they should affect the final result or they can be simply ignored;
- the scores are calculated and stored.
You can separately analyze each task by following its link. You will find details related to the used gold standard datasets, the configuration of the model(s), and the computed evaluation metrics.
Framework details
Parameters
| Parameter | Default | Options | Mandatory | Used_by |
|---|---|---|---|---|
| vector_file | - | vector file path | <ul><li>- [x] </li></ul> | all |
| vector_file_format | TXT | TXT, HDF5 | data_manager | |
| vector_size | 200 | numeric value | data_manager | |
| tasks | _all | Class, Reg, Clu, EntRel, DocSim, SemAn | evaluation_manager | |
| parallel | False | boolean | evaluation_manager | |
| debugging_mode | False | boolean | * | |
| similarity_metric | cosine | Sklearn affinity metrics | Clu, DocSim | |
| analogy_function | None (to use the default_analogy_function) | handler to function | semantic_analogy | |
| top_k | 2 | numeric value | SemAn | |
| compare_with | _all | list of run IDs | evaluation_manager |
-
analogy function details: the semantic analogy task takes a quadruplet of vectors (a,b,c,d) and it verifies if by manipulating the first three vectors it is possible to predict the last one. The manipulation happens by the analogy function.
def default_analogy_function(a,b,c){return b-a+c}Any other handler to function has to take as input 3 vectors and return a predicted vector, which will be compared with the last vector in each semantic quadruplet.
-
top_k is used by the semantic analogy task: the predicted vector is compared with the top_k closest vectors. If the actual d vector is among those, the task is considered correct.
Vector file format
The input file can be provided either as a plain text (also called TXT) file or as a HDF5.
The TXT file must be a white-space separated value file with a line for each embedded entity. Each row must contain the IRI of the embedded entity - without angular brackets - and its vector representation.
The HDF5 vectors file must be an H5 file with a single group called Vectors.
In this group, there must be a dataset for each entity with the base32 encoding of the entity name as the dataset name and the embedded vector as its value.
Running details
The evaluation framework can be run from the command line. Users can customize the evaluation settings by: 1) specifying parameters on the command line (useful when only a few settings must be specified and the user desires to use the default value for most of the parameters); 2) organizing them in an XML file (especially useful when there is the need to define most of the parameters); 3) passing them to a function that starts the evaluation.
In the example folder of the project on GitHub, there are examples for the different ways to provide the parameters.
To execute one of them you can move the desired main file at the top level of the project and then run it.
Note: The tasks can be executed sequentially or in parallel. If the code raises MemoryError it means that the tasks need more memory than the one available. In that case, run all the tasks sequentially.
Results storage
For each task and each file used as a gold standard, the framework will create
1) an output file that contains a reference to the file used as a gold standard and all the information related to evaluation metric(s) provided by each task,
2) a file containing all the missing entities,
3) a log file reporting extra information, occurred problems, and execution time,
4) information related to the comparison with previous runs.
In particular, about the comparison, it reports the values effectively considered in the comparison and the ranking of the current run upon the other ones. The results of each run are stored in the directory _results/result_
In Evaluation-Framework/tutorial_results_interpretation folder you can find some examples of produced output folders and some tutorials to interpret results.
Dataset to generate embeddings
We used a subset of English DBpedia 2016-04 (around 60M triples including 5M entities/instances). The considered dataset consists of instance types, skos categories, article categories, transitive instance types and mapping based objects.
Used datasets can be downloaded to the following links:
| SHA-1 | File Name |
|---|---|
| b3d1e5c5ef25c85dd89995732a5957e21de29ead | article_categories_en.ttl |
| 29fec5589a51d175ef11adcb0f7e5f6821c7ed9c | instance_types_en.ttl |
| 3001cb5898fda21b590abab936c75cb04783c731 | instance_types_transitive_en.ttl |
| f2268b9d19bdbd7abfcad408e82805bd81f29610 | mappingbased_objects_en.ttl |
| 887e02a41e69476eabd0df285a7f76d9cd6bf433 | skos_categories_en.ttl |
And then (optionally) concatenate (in alphabetic order of the file names):
| SHA-1 | File Name |
|---|---|
| 4127b5d0eb6ecc45350e7f0c619b3b6b88c3c24c | allData.nt |
Dependencies
The framework is tested to work with Python 3.7.
The required dependencies are: Numpy==1.14.0, Pandas==0.22.0, Scikit-learn==0.19.2, Scipy==1.1.0, H5py==2.8.0, unicodecsv==0.14.1.
License
The Apache license applies to the provided source code. For the datasets, please check the licensing information. For example, for the licensing information of the classification and regression datasets, see here; for Entity Relatedness task, see here.
Cite
@inproceedings{DBLP:conf/esws/PellegrinoCGR19,
author = {Maria Angela Pellegrino and
Michael Cochez and
Martina Garofalo and
Petar Ristoski},
title = {A Configurable Evaluation Framework for Node Embedding Techniques},
booktitle = {The Semantic Web: {ESWC} 2019 Satellite Events - {ESWC} 2019 Satellite Events, Portoro{\v{z}}, Slovenia, June 2-6, 2019, Revised Selected Papers},
pages = {156--160},
year = {2019},
crossref = {DBLP:conf/esws/2019s},
url = {https://doi.org/10.1007/978-3-030-32327-1\_31},
doi = {10.1007/978-3-030-32327-1\_31},
timestamp = {Thu, 28 Nov 2019 10:44:54 +0100},
biburl = {https://dblp.org/rec/bib/conf/esws/PellegrinoCGR19},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
History
To get the Evaluation Framework history, you can follow this link.